多水平统计模型在Meta分析中的应用研究
作者:李晓松 刘巧兰 倪宗瓒
单位:华西医科大学卫生统计学教研室(610041)
关键词:多水平模型;Meta分析;混合效应;影响因素
中国卫生统计990302 【提 要】 目的 探讨多水平模型技术在Meta分析中的应用价值。方法 根据Meta分析只能得到研究水平数据的特点,探讨了两水平随机效应与混合效应模型的建模方法。结果 获得平均“效应尺度”及其标准误的估计,以及与研究结果差异有关因素的估计。结论 在Meta分析中,多水平统计模型不仅可估计平均“效应尺度”及其可信区间,而且可分析与研究结果差异有关的影响因素。
Meta Analysis Using Multilevel Models.
Li Xiaosong,et al.,Department of Health Statistics,West China University of Medical Sciences(610041),Chengdu
, http://www.100md.com
【Abstract】 Objective to explore the applicability of multilevel statistical models in Meta analysis.Methods based on the characteristic of that data only in study-level can be available in Meta analysis,explored the modeling of two level random effects and mixed effects models.Results the estimates of the mean effect magnitude,its standard error,and the factors associated with the effect magnitude were obtained.Conclusion in Meta analysis,both the mean effect magnitude and its confidence interval,and the influence factors can be estimated by fitting multilevel models.
, 百拇医药
【Key words】 Multilevel model Meta analysis Mixed effect Influence factor
Meta分析是指对具有相同研究假设的多项独立研究结果所进行的合并分析〔1〕,主要目的是为了得到比单一研究更精确的结果估计,进一步的目的则是分析影响研究结果间差异的因素〔2〕。目前,Meta分析主要根据研究的“效应尺度”(effect magnitude)的齐性检验结果,决定采用固定效应模型(fixed effects model)或随机效应模型(random effects model)来合并每项研究的“效应尺度”,但一般难以分析影响研究结果间差异的因素。
多水平统计模型(multilevel statistical models)是国外教育学界80年代中后期发展起来的一门多元统计分析新技术,是当前国际上统计学研究中一个新兴而重要的领域〔2〕。本文将多水平模型应用于Meta分析,拟通过具有协变量的混合效应(mixed effects)多水平模型的建模,估计各项研究的平均“效应尺度”及其可信区间,同时探讨与研究结果差异有关的影响因素。
, 百拇医药
资料与方法
本文采用光盘检索了英文MEDLINE1990~1996年、中文“中国生物医学”(CBM)1984~1996年的有关吸烟与肺癌关系研究的文献,在已检索到的文献基础上回顾追踪同类文献至70年代,共查到文献49篇。各项研究独立且研究假设相同,可以得到的数据包括各项研究的ln(OR)值及其标准误、研究水平上的有关协变量包括样本含量、设计类型以及是否进行性别调整等。
Meta分析在合并不同来源的研究资料时可能引入异质方差(heterogeneous variance),其数据可看成具有两个水平的层次结构(hierarchical structure),即研究水平(水平2)与研究对象水平(水平1)。对于具有层次结构特征的数据,多水平模型可将传统模型中单一的随机误差项分解到与数据层次结构相对应的水平上,即分解出研究水平的变异,并提供了进一步拟合研究水平上复杂误差结构的可能性。
现以基本的两水平随机效应模型为例,说明模型结构与假设〔2〕:
, 百拇医药
yij=β0j+eij
j=1,2,…m,示水平2单位,i=1,2,…,nj,示水平1单位。
β0j为随机变量:β0j=β0+u0j
代入上式有:yij=β0+u0j+eij
水平2残差u0j亦为随机变量:u0j~N(0,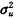 )
)
水平1残差eij即通常的残差项:eij~N(0,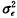 )
)
, http://www.100md.com
值得指出,尽管可将数据看成具有两个水平的层次结构,但Meta分析中能够得到的数据一般是研究结果即“效应尺度”及其标准误以及样本含量等,研究对象即个体的数据通常是不可得的,换言之,一般只能得到水平2单位的数据,而不能得到水平1单位的数据。因此,根据Meta分析资料的特点,我们拟合加权的水平2(聚集水平)模型,其建模方法具有其特殊性,基本模型可表达为:
y.j=β0+u.j+e.j
Var(u.j)=σ2u
Var(e.j)=σ2e/nj
总方差为+/nj,式中nj为第j项研究的样本含量,可通过对随机部分定义两个设计变量来拟合模型,即: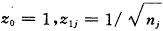
, http://www.100md.com
其随机系数分别为u.j和e.j。如果每项研究中的研究对象数目相等,则只需一个设计变量z0,但这种情形几乎不存在。反之,则需使用设计变量z1j。
在模型中进一步引入研究水平的协变量,模型一般可表达为:
y.j=β0+∑hβhxh.j+u.j+e.j
根据本资料特点,考虑两类模型:模型1为无任何协变量的随机效应模型,模型2为引入研究水平协变量的混合效应模型。
模型1:
y.j=β0+u.j+e.jz1j
, 百拇医药
y.j为第j个研究的ln(ORj),β0为合并全部ln(ORj)的平均估计值,u.j为第j个研究的随机效应,其分布为u.j~N(0,),e.j为与第j个研究有关的随机误差,其分布为e.j~N(0,/nj),Cov(u.j,e.j)=0。
模型2:
y.j=β0+β1x1.j+β2x2.j+u.j+e.jz1j
, 百拇医药
将性别调整(未调整取0,调整取1)和设计类型(病例对照研究取0,队列研究取1)两个协变量先后引入模型,分别对应于x1.j和x2.j ,将其效应拟合为固定效应,以解释研究结果间的差异,用一个随机成分u.j拟合其剩余部分。
结果与分析
表1 模型1的拟合结果
估计值
标准误
固定参数β0
1.4420
0.1140
随机参数σ2u(水平2)
, 百拇医药
0.6355
0.1287
σ2e(水平1)
1.0000
0.0000
根据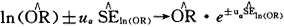 ,可计算平均“效应尺度”OR的估计为eβ0=4.2291,95%可信区间为4.2291×e±1.96×0.1140。研究之间的方差估计为0.6355,标准误为0.1278。表2 模型2中同时引入性别调整的拟合结果
,可计算平均“效应尺度”OR的估计为eβ0=4.2291,95%可信区间为4.2291×e±1.96×0.1140。研究之间的方差估计为0.6355,标准误为0.1278。表2 模型2中同时引入性别调整的拟合结果
, http://www.100md.com
估计值
标准误
固定参数β0
1.5460
0.1552
β1
-0.2219
0.2264
随机参数σ2u(水平2)
0.6245
0.1263
, http://www.100md.com σ2e(水平1)
1.0000
0.0000
可见,研究的“效应尺度”与性别是否调整有关,其系数估计为负,表明性别调整后ln(OR)值降低。结果表明,调整性别的OR估计为e1.3241=3.7588,未调整性别的OR估计为e1.5460=4.6927。同时,研究间方差估计从0.6355下降为0.6245,表明性别调整这一因素解释了部分研究结果间的变异。表3 模型2中同时引入性别调整与设计类型的拟合结果
估计值
标准误
固定参数β0
, 百拇医药
1.6180
0.1804
β1
-0.2950
0.2437
β2
-0.2682
0.3474
随机参数σ2u(水平2)
0.6162
0.1248
, 百拇医药
σ2e(水平1)
1.0000
0.0000
结果表明,研究的“效应尺度”与性别调整和设计类型有关,前者影响略大,两者系数估计均为负值,表明性别调整和队列研究的ln(OR)较低。根据两个协变量的取值可分别计算得到,未调整性别的病例对照研究的OR估计为5.0430,未调整性别的队列研究的OR估计为3.8567,调整性别的病例对照研究的OR估计为3.7547,调整性别的队列研究的OR估计为2.8714。研究间方差估计从0.6245进一步下降为0.6162,表明设计类型的不同亦解释了部分研究结果间的变异。讨 论
1.根据本文分析结果,如果对各项研究的“效应尺度”直接进行合并得到的平均“效应尺度”OR的估计为4.2291,其95%可信区间为3.3823~5.2879,但研究之间的方差估计为0.6355,提示研究结果之间具有较大的不同一性。进一步的分析结果表明,“效应尺度”的大小与是否进行性别调整以及设计类型有关,对这两个因素进行调整后,OR估计值明显下降,其中调整了性别这一混杂因素的队列研究的OR估计为2.8714,从流行病学专业知识可知,这一结果应更接近吸烟与肺癌实际的联系强度。值得指出,在引入两个研究水平的解释变量后,尽管研究间方差估计最低,但仍为0.6162。提示尚存在其他因素导致研究结果间的变异,如果可得到这些研究水平的影响因素,则可通过多水平模型进一步评价其效应。
, 百拇医药
2.通常采用的固定效应模型和随机效应模型亦可得到平均“效应尺度”及其可信区间的估计,但一般难以分析影响研究结果间差异的因素〔1〕。固定效应模型假定各项研究都估计一个相同而未知的总体效应值,但各项研究的“效应尺度”有时具有很大的不同一性,如本文资料。因此,随机效应模型假定各项研究估计其自身未知的研究效应,它们围绕一个未知的总体效应而分布,这可以看成是多水平模型中最基本的无协变量的情形〔2),即本文所拟合的随机效应模型(模型1)。应用多水平模型进行Meta分析的最大优点在于,可进一步在模型中引入水平2协变量以探讨影响研究结果间差异的因素。如本文所拟合的混合效应模型(模型2),用固定的协变量尽可能解释研究间的差别,用一个随机成分拟合其剩余部分,从而正确评价研究水平的影响因素对研究结果的效应。此外,多水平模型还提供了进一步拟合各水平复杂误差结构的可能性,这一问题将另文讨论。
参考文献
1.Hedges,LV.et al.Statistical Methods for Meta-Analysis.Orlando,Florida:Academic Press.1985.
2.Goldstein,H.Multilevel Statistical Models.London:Edward Arnold.1995., 百拇医药
单位:华西医科大学卫生统计学教研室(610041)
关键词:多水平模型;Meta分析;混合效应;影响因素
中国卫生统计990302 【提 要】 目的 探讨多水平模型技术在Meta分析中的应用价值。方法 根据Meta分析只能得到研究水平数据的特点,探讨了两水平随机效应与混合效应模型的建模方法。结果 获得平均“效应尺度”及其标准误的估计,以及与研究结果差异有关因素的估计。结论 在Meta分析中,多水平统计模型不仅可估计平均“效应尺度”及其可信区间,而且可分析与研究结果差异有关的影响因素。
Meta Analysis Using Multilevel Models.
Li Xiaosong,et al.,Department of Health Statistics,West China University of Medical Sciences(610041),Chengdu
, http://www.100md.com
【Abstract】 Objective to explore the applicability of multilevel statistical models in Meta analysis.Methods based on the characteristic of that data only in study-level can be available in Meta analysis,explored the modeling of two level random effects and mixed effects models.Results the estimates of the mean effect magnitude,its standard error,and the factors associated with the effect magnitude were obtained.Conclusion in Meta analysis,both the mean effect magnitude and its confidence interval,and the influence factors can be estimated by fitting multilevel models.
, 百拇医药
【Key words】 Multilevel model Meta analysis Mixed effect Influence factor
Meta分析是指对具有相同研究假设的多项独立研究结果所进行的合并分析〔1〕,主要目的是为了得到比单一研究更精确的结果估计,进一步的目的则是分析影响研究结果间差异的因素〔2〕。目前,Meta分析主要根据研究的“效应尺度”(effect magnitude)的齐性检验结果,决定采用固定效应模型(fixed effects model)或随机效应模型(random effects model)来合并每项研究的“效应尺度”,但一般难以分析影响研究结果间差异的因素。
多水平统计模型(multilevel statistical models)是国外教育学界80年代中后期发展起来的一门多元统计分析新技术,是当前国际上统计学研究中一个新兴而重要的领域〔2〕。本文将多水平模型应用于Meta分析,拟通过具有协变量的混合效应(mixed effects)多水平模型的建模,估计各项研究的平均“效应尺度”及其可信区间,同时探讨与研究结果差异有关的影响因素。
, 百拇医药
资料与方法
本文采用光盘检索了英文MEDLINE1990~1996年、中文“中国生物医学”(CBM)1984~1996年的有关吸烟与肺癌关系研究的文献,在已检索到的文献基础上回顾追踪同类文献至70年代,共查到文献49篇。各项研究独立且研究假设相同,可以得到的数据包括各项研究的ln(OR)值及其标准误、研究水平上的有关协变量包括样本含量、设计类型以及是否进行性别调整等。
Meta分析在合并不同来源的研究资料时可能引入异质方差(heterogeneous variance),其数据可看成具有两个水平的层次结构(hierarchical structure),即研究水平(水平2)与研究对象水平(水平1)。对于具有层次结构特征的数据,多水平模型可将传统模型中单一的随机误差项分解到与数据层次结构相对应的水平上,即分解出研究水平的变异,并提供了进一步拟合研究水平上复杂误差结构的可能性。
现以基本的两水平随机效应模型为例,说明模型结构与假设〔2〕:
, 百拇医药
yij=β0j+eij
j=1,2,…m,示水平2单位,i=1,2,…,nj,示水平1单位。
β0j为随机变量:β0j=β0+u0j
代入上式有:yij=β0+u0j+eij
水平2残差u0j亦为随机变量:u0j~N(0,
)水平1残差eij即通常的残差项:eij~N(0,
), http://www.100md.com
值得指出,尽管可将数据看成具有两个水平的层次结构,但Meta分析中能够得到的数据一般是研究结果即“效应尺度”及其标准误以及样本含量等,研究对象即个体的数据通常是不可得的,换言之,一般只能得到水平2单位的数据,而不能得到水平1单位的数据。因此,根据Meta分析资料的特点,我们拟合加权的水平2(聚集水平)模型,其建模方法具有其特殊性,基本模型可表达为:
y.j=β0+u.j+e.j
Var(u.j)=σ2u
Var(e.j)=σ2e/nj
总方差为
+/nj,式中nj为第j项研究的样本含量,可通过对随机部分定义两个设计变量来拟合模型,即:, http://www.100md.com
其随机系数分别为u.j和e.j。如果每项研究中的研究对象数目相等,则只需一个设计变量z0,但这种情形几乎不存在。反之,则需使用设计变量z1j。
在模型中进一步引入研究水平的协变量,模型一般可表达为:
y.j=β0+∑hβhxh.j+u.j+e.j
根据本资料特点,考虑两类模型:模型1为无任何协变量的随机效应模型,模型2为引入研究水平协变量的混合效应模型。
模型1:
y.j=β0+u.j+e.jz1j
, 百拇医药
y.j为第j个研究的ln(ORj),β0为合并全部ln(ORj)的平均估计值,u.j为第j个研究的随机效应,其分布为u.j~N(0,
),e.j为与第j个研究有关的随机误差,其分布为e.j~N(0,/nj),Cov(u.j,e.j)=0。模型2:
y.j=β0+β1x1.j+β2x2.j+u.j+e.jz1j
, 百拇医药
将性别调整(未调整取0,调整取1)和设计类型(病例对照研究取0,队列研究取1)两个协变量先后引入模型,分别对应于x1.j和x2.j ,将其效应拟合为固定效应,以解释研究结果间的差异,用一个随机成分u.j拟合其剩余部分。
结果与分析
表1 模型1的拟合结果
估计值
标准误
固定参数β0
1.4420
0.1140
随机参数σ2u(水平2)
, 百拇医药
0.6355
0.1287
σ2e(水平1)
1.0000
0.0000
根据
,可计算平均“效应尺度”OR的估计为eβ0=4.2291,95%可信区间为4.2291×e±1.96×0.1140。研究之间的方差估计为0.6355,标准误为0.1278。表2 模型2中同时引入性别调整的拟合结果, http://www.100md.com
估计值
标准误
固定参数β0
1.5460
0.1552
β1
-0.2219
0.2264
随机参数σ2u(水平2)
0.6245
0.1263
, http://www.100md.com σ2e(水平1)
1.0000
0.0000
可见,研究的“效应尺度”与性别是否调整有关,其系数估计为负,表明性别调整后ln(OR)值降低。结果表明,调整性别的OR估计为e1.3241=3.7588,未调整性别的OR估计为e1.5460=4.6927。同时,研究间方差估计从0.6355下降为0.6245,表明性别调整这一因素解释了部分研究结果间的变异。表3 模型2中同时引入性别调整与设计类型的拟合结果
估计值
标准误
固定参数β0
, 百拇医药
1.6180
0.1804
β1
-0.2950
0.2437
β2
-0.2682
0.3474
随机参数σ2u(水平2)
0.6162
0.1248
, 百拇医药
σ2e(水平1)
1.0000
0.0000
结果表明,研究的“效应尺度”与性别调整和设计类型有关,前者影响略大,两者系数估计均为负值,表明性别调整和队列研究的ln(OR)较低。根据两个协变量的取值可分别计算得到,未调整性别的病例对照研究的OR估计为5.0430,未调整性别的队列研究的OR估计为3.8567,调整性别的病例对照研究的OR估计为3.7547,调整性别的队列研究的OR估计为2.8714。研究间方差估计从0.6245进一步下降为0.6162,表明设计类型的不同亦解释了部分研究结果间的变异。讨 论
1.根据本文分析结果,如果对各项研究的“效应尺度”直接进行合并得到的平均“效应尺度”OR的估计为4.2291,其95%可信区间为3.3823~5.2879,但研究之间的方差估计为0.6355,提示研究结果之间具有较大的不同一性。进一步的分析结果表明,“效应尺度”的大小与是否进行性别调整以及设计类型有关,对这两个因素进行调整后,OR估计值明显下降,其中调整了性别这一混杂因素的队列研究的OR估计为2.8714,从流行病学专业知识可知,这一结果应更接近吸烟与肺癌实际的联系强度。值得指出,在引入两个研究水平的解释变量后,尽管研究间方差估计最低,但仍为0.6162。提示尚存在其他因素导致研究结果间的变异,如果可得到这些研究水平的影响因素,则可通过多水平模型进一步评价其效应。
, 百拇医药
2.通常采用的固定效应模型和随机效应模型亦可得到平均“效应尺度”及其可信区间的估计,但一般难以分析影响研究结果间差异的因素〔1〕。固定效应模型假定各项研究都估计一个相同而未知的总体效应值,但各项研究的“效应尺度”有时具有很大的不同一性,如本文资料。因此,随机效应模型假定各项研究估计其自身未知的研究效应,它们围绕一个未知的总体效应而分布,这可以看成是多水平模型中最基本的无协变量的情形〔2),即本文所拟合的随机效应模型(模型1)。应用多水平模型进行Meta分析的最大优点在于,可进一步在模型中引入水平2协变量以探讨影响研究结果间差异的因素。如本文所拟合的混合效应模型(模型2),用固定的协变量尽可能解释研究间的差别,用一个随机成分拟合其剩余部分,从而正确评价研究水平的影响因素对研究结果的效应。此外,多水平模型还提供了进一步拟合各水平复杂误差结构的可能性,这一问题将另文讨论。
参考文献
1.Hedges,LV.et al.Statistical Methods for Meta-Analysis.Orlando,Florida:Academic Press.1985.
2.Goldstein,H.Multilevel Statistical Models.London:Edward Arnold.1995., 百拇医药