��ˮƽģ���ڽ���������Ϸ����е�Ӧ��
���ߣ������� ����ͮ �����
��λ������ҽ�ƴ�ѧ����ͳ��ѧ������(610041)
�ؼ��ʣ���ˮƽģ�ͣ�������ƣ�˳��ЧӦ
�й�����ͳ��990506 ���� Ҫ�� Ŀ�� ̽�ֶ�ˮƽģ���ڽ���������Ϸ����е�Ӧ�ü�ֵ������ ͨ����ˮƽ���ϵ��ģ���Լ�˳��ЧӦ����ϣ����ƴ���ЧӦ�Ĵ�С�����ڸ����ı��졣��� �ֱ��ô���ЧӦ����ЧӦ��˳��ЧӦ�Լ��������Ĺ��ơ����� �ڽ���������Ϸ����У�������˳��ЧӦʱ����ˮƽģ�ͿɷֽⲢ����˳��ЧӦ�Ĵ�С��ͬʱ�õ�����ЧӦ�ͽ�ЧӦ�Ĺ��ơ�
Multilevel Models in Analysis of Crossover Design
Li Xiaosong,Zhang Wentong,Ni Zongzan.
, ��Ĵҽҩ
Department of Health Statistics,West China University of Medical Sciences(610041),Chengdu
��Abstract�� Objective To explore the special applicability of the multilevel models in analysis of crossover design.Methods Fitting two-level random coefficient model and sequence effect to estimate the treatment effect and its variation between individuals.Results Obtain the estimates of treatment effect,time period effect,sequence effect and individual variation separately.Conclusion While the sequence effect exists in analysis of crossover design,the sequence effect can be decomposed and tested,meanwhile,the treatment effect and the time period effect can be estimated by fitting multilevel models.
, ��Ĵҽҩ
��Key words�� Multilevel model Crossover design Sequence effect
�������(crossover design)���ٴ������бȽ����ִ�����ʩA��BЧ���ij��÷��������ɷ����������ڴ�����ʩ�䡢�μ��Լ������IJ�������ǿɽ���������Ӵ�����ʩ�ıȽ����ų���7����һ����Ϊ��A��B���ִ����Ⱥ�����Ļ�����ȣ�ƽ��������˳��Խ����Ӱ�졣���A��B���ִ���������һ����Ӱ���Ӱ����ͬ������������˳���أ���֮����A������ЧӦӰ����һ��B������ЧӦ����B��Ӱ��A������A��������һ��B������Ӱ�첻���� B�� A��Ӱ�죬������˳���ЧӦ��ͬ��5��6������ˣ�˳��ЧӦ(sequence effect)��һ���̶��Ϸ�ӳ�˲���ЧӦ(carry-over effect)�Ĵ�С������һ�εĴ�������ЧӦȥ��ʱ��(washout time)���������ԭ���������һ�εĴ���Ч����Ŀǰ������Ƴ��õ�ͳ�Ʒ�����һ��δ���Dz���ЧӦ�����������ܲ�����DZ��Ӱ�졣
, http://www.100md.com
�����뷽��
Ϊ�о�A��B�������Ʒ�����ϸ������֢������Ч�IJ��������ķ�����50����������A�������ƣ����һ��ʱ�������B�������ƣ�����50������������B���������ͬ��ʱ������A�������ƣ�ͬʱ��¼���ƺ�İ�ϸ�����������ٴ������г�������ȫ���������ƣ�����ÿ�����Զ����������ظ��������ظ������������Ƕ������ݣ�����������ˮƽ�Ľṹ��������ˮƽ(ˮƽ2)���ظ�������(ˮƽ1)����ˮƽģ��(multilevel model)�ɴӲ���ֵ���������зֽ�������������죬��Ϊ��һ����ϻ���ˮƽ�������ˮƽ�ĸ������ṹ�ṩ�˿�������1�������Ľ���ˮƽģ��Ӧ���ڽ���������ϵķ�����ͨ����ˮƽ���ϵ��ģ���Լ�˳��ЧӦ����ϣ����ƴ���ЧӦ�Ĵ�С�����ڻ���ı��졣
����yij��ʾ��j�����ߵĵ�i�ΰ�ϸ������������x1ij��ʾA��B�������Ʒ���(����)���Ʊ�����x2ij��ʾ��������ε��Ʊ��������Ǿ�Ϊ0��1��������������ˮƽģ��(ģ��1)�ɱ���Ϊ��
, ��Ĵҽҩ
yij=��0+��1x��1ij+��2x2ij+u0j+eij
(1)
j=1,2����,100,ʾ����(ˮƽ2��λ)��i=1,2,ʾ�ظ�����ֵ(ˮƽ1��λ)����Ϊ�̶�ЧӦ����ֵ��ˮƽ2�в�u0jΪ���������u0j��N(0��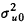 )���в�������ӳ�˻�����졣ˮƽ1�в�eij��ͨ���IJв��eij��N(0��
)���в�������ӳ�˻�����졣ˮƽ1�в�eij��ͨ���IJв��eij��N(0��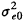 )����ӳ�˻����ڱ��졣
)����ӳ�˻����ڱ��졣
, ��Ĵҽҩ
����������IJ����ˮƽ2�Ļ�����ڱ��죬����ģ��ˮƽ2����������x1ij�����ϵ��������ӳ���������Ʒ�����ÿ����������ϸ�������ö������Ų��졣��ˮƽ���ϵ��ģ��(ģ��2)�ɱ���Ϊ��
yij=��0+��1x1ij+��2x2ij+u0j+u1jx1ij+eij
(2)
��ǰ������������ƿ��ܴ��ڵ���Ҫ����֮һ������ν�IJ���ЧӦ������ǰ���Ʒ�����ЧӦ�����ٵ�Ӱ�쵽ijЩ���߶Եڶ������Ʒ����ķ�Ӧ������֮��u1j������ʵʩ������˳���йء�Ϊ���������ЧӦ������ģ�͵������������һ��������u3j��3ij��1������3ijΪ��ʾ����˳����Ʊ�������ΪAB˳��3ijȡ1����֮��BA˳��ȡ0�������ϵ��u3j�IJ�������ֵ��2u3��Ϊ˳��ЧӦ�Ĺ��ƣ����ǽ�ˮƽ2�������Ϊ����˳��ĺ�������˳��ͬ���������ڻ���ı��첻ͬ��ʵ�������ڻ�������н�һ���ֽ��˳���ЧӦ��ģ��3�ɱ���Ϊ��
, http://www.100md.com
yij=��0+��1x1ij+��2x2ij+u0j+u1jx1ij+u3j��3ij+eij
(3)
ģ��2��3��δ���ˮƽ2���ϵ�����Э����䷽��Э����ṹΪ��
��������
��1 ģ��1����Ͻ��
����ֵ
����
, http://www.100md.com
�̶����֦�0
5.7140
0.2230
��1
1.3990
0.2364
��2
0.2563
0.2642
�������
ˮƽ2 ��2u0
, http://www.100md.com
2.2770
0.6280
ˮƽ1 ��2e0
8.3810
0.6829
-2log-likelihood
2108.34
ģ�̶����ֲ�������ֵ�ļ������ɲ���Walds���飬��k�������Ħ�2ֵΪ[��k/SE(��k)]2�����ɶ�Ϊ1�����������A��B���ִ���ЧӦ�IJ�����ͳ��ѧ����(��2=35.02��P<0.005)����������ЧӦ�IJ����ͳ��ѧ����(��2=0.94��P>0.25)������ģ��2�н�һ����ϴ���ЧӦ��ˮƽ2������������(��2)����2 ģ��2����Ͻ��
, http://www.100md.com
����ֵ
����
�̶����֦�0
5.9760
0.1510
��1
1.4016
0.2340
��2
0.1624
0.1875
�������
, ��Ĵҽҩ
ˮƽ2 ��2u0
2.0040
0.4936
��2u1
12.9700
1.4160
ˮƽ1 ��2e0
2.1610
0.4931
-2log-likelihood
1964.02
, ��Ĵҽҩ
�ӱ�2�ɼ�������ЧӦ�ڻ�����ڽϴ�ı��졣ģ��������ֲ�������ֵһ����ö�����Ȼ�ȼ��飬���������������IJ����ˮƽ2���������������ͳ��ѧ����(��2=144.32��P<0.005)��ͬʱ��ˮƽ1�в���ģ��1��8.3810�½�Ϊ2.1610����ʾˮƽ1�Ļ����ڱ�����Ҫ���ɴ���ЧӦ��������3 ģ��3����Ͻ��
����ֵ
����
�̶����֦�0
6.0430
0.1354
��1
1.4210
, ��Ĵҽҩ
0.2407
��2
0.1413
0.1826
�������
ˮƽ2 ��2u0
1.3760
0.5080
��2u1
13.8400
1.4540
, ��Ĵҽҩ
��2u3
1.8880
0.6483
ˮƽ1 ��2e0
1.7450
0.4715
-2log-likelihood
1955.92
ģ��2��3�Ķ�����Ȼ�ȼ�����������˳��ЧӦ����ͳ��ѧ����(��2=8.10��P<0.005)��ģ��3������ֵ���Ͻ��������ˮƽ2�ܷ���Ϊx1ij�ͦ�3ij�ĺ��������������ڻ�����ܱ����������Ʒ���������˳��ı仯���仯���� ��
, ��Ĵҽҩ
����ЧӦͨ��ָҩ�����ЧӦ(drug carry��over effect)�����⣬���е�һ����ҩ������ҩ�Զ������ij���ЧӦ(withdrawal effect)������ЧӦ(psychological carry��over effect)����������״������ҩ���ı������µ�����ЧӦ(nonuniform carry -effect)�ȵ���4���������ƺ���������������֮�����㹻��ʱ���Լ��ϸ���ѭ˫ä���ȣ����ϸ���ЧӦ��Ӱ���С���ɲ���ͨ���Ľ�����Ʒ������������ķ�������� t������Ⱥͼ������������������Լ������ЧӦ��7������֮����Ӧ���ǵ�����ЧӦ�������������DZ��Ӱ�졣
����������ݵı�����Դ�ɷֽ�Ϊ����ЧӦ����ЧӦ��˳��ЧӦ������졣��˳��ЧӦ�ķֽ⼰���飬���õ��з������������˳��ЧӦ�ı���(����)��ͬһ˳�����ڸ�������(����)֮�ȼ������ͳ����F��5��9������һ�ַ�������ν������������ͬһ���������ЧӦ��ӣ���AB��BA����˳��������t������Ⱥͼ�����3��8���������ַ���ʵ�����ǵȼ۵ġ������ϲ��÷������������FֵΪ10.52�� P<0.01��˳��ЧӦ�IJ����ͳ��ѧ���壻���ú������������˳��ЧӦ�IJ��(tֵΪ3.24�� P<0.01)����˳��ЧӦ����ʱ���Դ���ЧӦ����ͳ���ƶϴ���һ��������2��������������ķ�������Լ������ķ�������ȷ�������һ�����⡣��˳��ЧӦ������������ĵڶ��Σ���������������ó���t������Ⱥͼ��������һ��������8�������ַ��������������Ϊ������ƽ��з�����������˳��ЧӦ�Դ���ЧӦ�ĸ��ţ��Դ���ЧӦ������ͳ���ƶ�����ƫ�ģ���ֻ������ȫ������һ�����Ϣ�����Լ���Ч�ܽϵ���2�������Ķ����ϵ�һ�����������ij���t��������� tֵΪ1.72�� P>0.05������ЧӦ��ͳ��ѧ���塣
, http://www.100md.com
��ˮƽģ�ͷ�����˳��ЧӦ��һ���Ӹ��������зֽ��������������ͳ��ѧ���壬ͬʱҲ�ɵõ������ͽ�ЧӦ�Ĺ��ƣ���������ˮƽģ��(ģ��1)�ɷֱ�õ��������ι̶�ЧӦ�Ĺ��ƣ��Լ��������ЧӦ�Ĺ��ƣ��������ȡ���Զ���������У����߷�ӳ�����Զ�������ı�����Ϣ�����ϵ��ģ��(ģ��2)��������ִ�����ʩ��ÿ�����Զ����ЧӦ��ģ��3�������������Զ������ܱ������Ϊ����˳���Լ�������ʩ�ĺ�����ͬʱ����ô����ͽι̶�ЧӦ�Ĺ��ơ����˷������ɽ���ˮƽģ�͵�Ӧ����չ�����ִ������������Σ��糣�������ִ��������ؽ��������1�������⣬ˮƽ1��������ڵı����а����˴�����ε�ЧӦ�����ǿɽ�һ������ˮƽ1���ӷ���ṹ���������ڱ���ֽ�Ϊ���������ͽμ�����Լ������������ijЩ����£�Ҳ�����ˮƽ1�в������ؽṹ��ʱ������ģ����1���������⽫�������ۡ�
�����
1.Goldstein H.Multilevel Statistical Models.London:Edward Arnold,1995,94-95.
, ��Ĵҽҩ
2.Senn SJ.The AB/BA crossover:past,present and future?Statistical Methods in Medical Research,1994,3:303.
3.Grizzle JE.The two-period change-over design and its use in clinical trials.Biometrics,1965,21:467.
4.Woods JR.The two-period crossover design in medical research.Annals of Internal Medicine,1989,110:560.
5.���泬.ҽ������ͳ�Ʒ���.��3��.�������������������磬1988,780-781.
6.������.�й�ҽѧ�ٿ�ȫ��*ҽѧͳ��ѧ�ֲ�.�Ϻ����Ϻ���ѧ���������磬1985.
7.�����.ҽѧͳ��ѧ.��2��.�������������������磬1998��87-90.
8.л¡��.����������������ͳ�Ʒ���.�й�����ͳ�ƣ�1991,8(3)��21.
9.�ձ��������岨.��������������Ϸ�����SAS����.�й�����ͳ�ƣ�1997,14(3)��52., ��Ĵҽҩ
��λ������ҽ�ƴ�ѧ����ͳ��ѧ������(610041)
�ؼ��ʣ���ˮƽģ�ͣ�������ƣ�˳��ЧӦ
�й�����ͳ��990506 ���� Ҫ�� Ŀ�� ̽�ֶ�ˮƽģ���ڽ���������Ϸ����е�Ӧ�ü�ֵ������ ͨ����ˮƽ���ϵ��ģ���Լ�˳��ЧӦ����ϣ����ƴ���ЧӦ�Ĵ�С�����ڸ����ı��졣��� �ֱ��ô���ЧӦ����ЧӦ��˳��ЧӦ�Լ��������Ĺ��ơ����� �ڽ���������Ϸ����У�������˳��ЧӦʱ����ˮƽģ�ͿɷֽⲢ����˳��ЧӦ�Ĵ�С��ͬʱ�õ�����ЧӦ�ͽ�ЧӦ�Ĺ��ơ�
Multilevel Models in Analysis of Crossover Design
Li Xiaosong,Zhang Wentong,Ni Zongzan.
, ��Ĵҽҩ
Department of Health Statistics,West China University of Medical Sciences(610041),Chengdu
��Abstract�� Objective To explore the special applicability of the multilevel models in analysis of crossover design.Methods Fitting two-level random coefficient model and sequence effect to estimate the treatment effect and its variation between individuals.Results Obtain the estimates of treatment effect,time period effect,sequence effect and individual variation separately.Conclusion While the sequence effect exists in analysis of crossover design,the sequence effect can be decomposed and tested,meanwhile,the treatment effect and the time period effect can be estimated by fitting multilevel models.
, ��Ĵҽҩ
��Key words�� Multilevel model Crossover design Sequence effect
�������(crossover design)���ٴ������бȽ����ִ�����ʩA��BЧ���ij��÷��������ɷ����������ڴ�����ʩ�䡢�μ��Լ������IJ�������ǿɽ���������Ӵ�����ʩ�ıȽ����ų���7����һ����Ϊ��A��B���ִ����Ⱥ�����Ļ�����ȣ�ƽ��������˳��Խ����Ӱ�졣���A��B���ִ���������һ����Ӱ���Ӱ����ͬ������������˳���أ���֮����A������ЧӦӰ����һ��B������ЧӦ����B��Ӱ��A������A��������һ��B������Ӱ�첻���� B�� A��Ӱ�죬������˳���ЧӦ��ͬ��5��6������ˣ�˳��ЧӦ(sequence effect)��һ���̶��Ϸ�ӳ�˲���ЧӦ(carry-over effect)�Ĵ�С������һ�εĴ�������ЧӦȥ��ʱ��(washout time)���������ԭ���������һ�εĴ���Ч����Ŀǰ������Ƴ��õ�ͳ�Ʒ�����һ��δ���Dz���ЧӦ�����������ܲ�����DZ��Ӱ�졣
, http://www.100md.com
�����뷽��
Ϊ�о�A��B�������Ʒ�����ϸ������֢������Ч�IJ��������ķ�����50����������A�������ƣ����һ��ʱ�������B�������ƣ�����50������������B���������ͬ��ʱ������A�������ƣ�ͬʱ��¼���ƺ�İ�ϸ�����������ٴ������г�������ȫ���������ƣ�����ÿ�����Զ����������ظ��������ظ������������Ƕ������ݣ�����������ˮƽ�Ľṹ��������ˮƽ(ˮƽ2)���ظ�������(ˮƽ1)����ˮƽģ��(multilevel model)�ɴӲ���ֵ���������зֽ�������������죬��Ϊ��һ����ϻ���ˮƽ�������ˮƽ�ĸ������ṹ�ṩ�˿�������1�������Ľ���ˮƽģ��Ӧ���ڽ���������ϵķ�����ͨ����ˮƽ���ϵ��ģ���Լ�˳��ЧӦ����ϣ����ƴ���ЧӦ�Ĵ�С�����ڻ���ı��졣
����yij��ʾ��j�����ߵĵ�i�ΰ�ϸ������������x1ij��ʾA��B�������Ʒ���(����)���Ʊ�����x2ij��ʾ��������ε��Ʊ��������Ǿ�Ϊ0��1��������������ˮƽģ��(ģ��1)�ɱ���Ϊ��
, ��Ĵҽҩ
yij=��0+��1x��1ij+��2x2ij+u0j+eij
(1)
j=1,2����,100,ʾ����(ˮƽ2��λ)��i=1,2,ʾ�ظ�����ֵ(ˮƽ1��λ)����Ϊ�̶�ЧӦ����ֵ��ˮƽ2�в�u0jΪ���������u0j��N(0��
)���в�������ӳ�˻�����졣ˮƽ1�в�eij��ͨ���IJв��eij��N(0��)����ӳ�˻����ڱ��졣, ��Ĵҽҩ
����������IJ����ˮƽ2�Ļ�����ڱ��죬����ģ��ˮƽ2����������x1ij�����ϵ��������ӳ���������Ʒ�����ÿ����������ϸ�������ö������Ų��졣��ˮƽ���ϵ��ģ��(ģ��2)�ɱ���Ϊ��
yij=��0+��1x1ij+��2x2ij+u0j+u1jx1ij+eij
(2)
��ǰ������������ƿ��ܴ��ڵ���Ҫ����֮һ������ν�IJ���ЧӦ������ǰ���Ʒ�����ЧӦ�����ٵ�Ӱ�쵽ijЩ���߶Եڶ������Ʒ����ķ�Ӧ������֮��u1j������ʵʩ������˳���йء�Ϊ���������ЧӦ������ģ�͵������������һ��������u3j��3ij��1������3ijΪ��ʾ����˳����Ʊ�������ΪAB˳��3ijȡ1����֮��BA˳��ȡ0�������ϵ��u3j�IJ�������ֵ��2u3��Ϊ˳��ЧӦ�Ĺ��ƣ����ǽ�ˮƽ2�������Ϊ����˳��ĺ�������˳��ͬ���������ڻ���ı��첻ͬ��ʵ�������ڻ�������н�һ���ֽ��˳���ЧӦ��ģ��3�ɱ���Ϊ��
, http://www.100md.com
yij=��0+��1x1ij+��2x2ij+u0j+u1jx1ij+u3j��3ij+eij
(3)
ģ��2��3��δ���ˮƽ2���ϵ�����Э����䷽��Э����ṹΪ��
��������
��1 ģ��1����Ͻ��
����ֵ
����
, http://www.100md.com
�̶����֦�0
5.7140
0.2230
��1
1.3990
0.2364
��2
0.2563
0.2642
�������
ˮƽ2 ��2u0
, http://www.100md.com
2.2770
0.6280
ˮƽ1 ��2e0
8.3810
0.6829
-2log-likelihood
2108.34
ģ�̶����ֲ�������ֵ�ļ������ɲ���Walds���飬��k�������Ħ�2ֵΪ[��k/SE(��k)]2�����ɶ�Ϊ1�����������A��B���ִ���ЧӦ�IJ�����ͳ��ѧ����(��2=35.02��P<0.005)����������ЧӦ�IJ����ͳ��ѧ����(��2=0.94��P>0.25)������ģ��2�н�һ����ϴ���ЧӦ��ˮƽ2������������(��2)����2 ģ��2����Ͻ��
, http://www.100md.com
����ֵ
����
�̶����֦�0
5.9760
0.1510
��1
1.4016
0.2340
��2
0.1624
0.1875
�������
, ��Ĵҽҩ
ˮƽ2 ��2u0
2.0040
0.4936
��2u1
12.9700
1.4160
ˮƽ1 ��2e0
2.1610
0.4931
-2log-likelihood
1964.02
, ��Ĵҽҩ
�ӱ�2�ɼ�������ЧӦ�ڻ�����ڽϴ�ı��졣ģ��������ֲ�������ֵһ����ö�����Ȼ�ȼ��飬���������������IJ����ˮƽ2���������������ͳ��ѧ����(��2=144.32��P<0.005)��ͬʱ��ˮƽ1�в���ģ��1��8.3810�½�Ϊ2.1610����ʾˮƽ1�Ļ����ڱ�����Ҫ���ɴ���ЧӦ��������3 ģ��3����Ͻ��
����ֵ
����
�̶����֦�0
6.0430
0.1354
��1
1.4210
, ��Ĵҽҩ
0.2407
��2
0.1413
0.1826
�������
ˮƽ2 ��2u0
1.3760
0.5080
��2u1
13.8400
1.4540
, ��Ĵҽҩ
��2u3
1.8880
0.6483
ˮƽ1 ��2e0
1.7450
0.4715
-2log-likelihood
1955.92
ģ��2��3�Ķ�����Ȼ�ȼ�����������˳��ЧӦ����ͳ��ѧ����(��2=8.10��P<0.005)��ģ��3������ֵ���Ͻ��������ˮƽ2�ܷ���Ϊx1ij�ͦ�3ij�ĺ��������������ڻ�����ܱ����������Ʒ���������˳��ı仯���仯���� ��
, ��Ĵҽҩ
����ЧӦͨ��ָҩ�����ЧӦ(drug carry��over effect)�����⣬���е�һ����ҩ������ҩ�Զ������ij���ЧӦ(withdrawal effect)������ЧӦ(psychological carry��over effect)����������״������ҩ���ı������µ�����ЧӦ(nonuniform carry -effect)�ȵ���4���������ƺ���������������֮�����㹻��ʱ���Լ��ϸ���ѭ˫ä���ȣ����ϸ���ЧӦ��Ӱ���С���ɲ���ͨ���Ľ�����Ʒ������������ķ�������� t������Ⱥͼ������������������Լ������ЧӦ��7������֮����Ӧ���ǵ�����ЧӦ�������������DZ��Ӱ�졣
����������ݵı�����Դ�ɷֽ�Ϊ����ЧӦ����ЧӦ��˳��ЧӦ������졣��˳��ЧӦ�ķֽ⼰���飬���õ��з������������˳��ЧӦ�ı���(����)��ͬһ˳�����ڸ�������(����)֮�ȼ������ͳ����F��5��9������һ�ַ�������ν������������ͬһ���������ЧӦ��ӣ���AB��BA����˳��������t������Ⱥͼ�����3��8���������ַ���ʵ�����ǵȼ۵ġ������ϲ��÷������������FֵΪ10.52�� P<0.01��˳��ЧӦ�IJ����ͳ��ѧ���壻���ú������������˳��ЧӦ�IJ��(tֵΪ3.24�� P<0.01)����˳��ЧӦ����ʱ���Դ���ЧӦ����ͳ���ƶϴ���һ��������2��������������ķ�������Լ������ķ�������ȷ�������һ�����⡣��˳��ЧӦ������������ĵڶ��Σ���������������ó���t������Ⱥͼ��������һ��������8�������ַ��������������Ϊ������ƽ��з�����������˳��ЧӦ�Դ���ЧӦ�ĸ��ţ��Դ���ЧӦ������ͳ���ƶ�����ƫ�ģ���ֻ������ȫ������һ�����Ϣ�����Լ���Ч�ܽϵ���2�������Ķ����ϵ�һ�����������ij���t��������� tֵΪ1.72�� P>0.05������ЧӦ��ͳ��ѧ���塣
, http://www.100md.com
��ˮƽģ�ͷ�����˳��ЧӦ��һ���Ӹ��������зֽ��������������ͳ��ѧ���壬ͬʱҲ�ɵõ������ͽ�ЧӦ�Ĺ��ƣ���������ˮƽģ��(ģ��1)�ɷֱ�õ��������ι̶�ЧӦ�Ĺ��ƣ��Լ��������ЧӦ�Ĺ��ƣ��������ȡ���Զ���������У����߷�ӳ�����Զ�������ı�����Ϣ�����ϵ��ģ��(ģ��2)��������ִ�����ʩ��ÿ�����Զ����ЧӦ��ģ��3�������������Զ������ܱ������Ϊ����˳���Լ�������ʩ�ĺ�����ͬʱ����ô����ͽι̶�ЧӦ�Ĺ��ơ����˷������ɽ���ˮƽģ�͵�Ӧ����չ�����ִ������������Σ��糣�������ִ��������ؽ��������1�������⣬ˮƽ1��������ڵı����а����˴�����ε�ЧӦ�����ǿɽ�һ������ˮƽ1���ӷ���ṹ���������ڱ���ֽ�Ϊ���������ͽμ�����Լ������������ijЩ����£�Ҳ�����ˮƽ1�в������ؽṹ��ʱ������ģ����1���������⽫�������ۡ�
�����
1.Goldstein H.Multilevel Statistical Models.London:Edward Arnold,1995,94-95.
, ��Ĵҽҩ
2.Senn SJ.The AB/BA crossover:past,present and future?Statistical Methods in Medical Research,1994,3:303.
3.Grizzle JE.The two-period change-over design and its use in clinical trials.Biometrics,1965,21:467.
4.Woods JR.The two-period crossover design in medical research.Annals of Internal Medicine,1989,110:560.
5.���泬.ҽ������ͳ�Ʒ���.��3��.�������������������磬1988,780-781.
6.������.�й�ҽѧ�ٿ�ȫ��*ҽѧͳ��ѧ�ֲ�.�Ϻ����Ϻ���ѧ���������磬1985.
7.�����.ҽѧͳ��ѧ.��2��.�������������������磬1998��87-90.
8.л¡��.����������������ͳ�Ʒ���.�й�����ͳ�ƣ�1991,8(3)��21.
9.�ձ��������岨.��������������Ϸ�����SAS����.�й�����ͳ�ƣ�1997,14(3)��52., ��Ĵҽҩ