编程小白的第一本Python入门书.pdf
http://www.100md.com
2020年1月3日
 |
| 第1页 |
 |
| 第6页 |
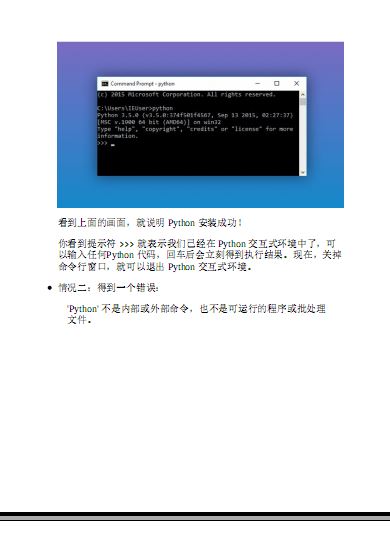 |
| 第20页 |
 |
| 第23页 |
 |
| 第41页 |
参见附件(4136KB,154页)。
编程小白的第一本Python入门书,这是一本编程小白必备的入门教程书籍,作者通过多年的工作经验编写出这本书,目的就是让新学校者能够快速上手编程。

Python入门书介绍
为了能让更多的编程小白轻松地入门编程,我把高效学习法结合Python中的核心知识,写成了这本书。随意翻上几页,你就会发现这本书和其他编程书的不同,其中有大量的视觉化场景帮你理解概念,穿插了若干有趣的小项目,最重要的是,这本书是为零基础小白而设计的。既然笨办法不能让我学会Python,那么我决定用一种聪明方法来学,为自己创造学习的捷径。
Python入门书作者
侯爵,麻瓜编程创始人。网易云课堂上最畅销的课程《Python 实战》系列课程讲师,目前已有超过4万名学员。设计专业背景,拥有设计与编程跨界思维,善于找到学习技能的最佳路径,擅长把复杂的东西简单的讲清楚。初学编程时,发现市面上很难找到适合小白的学习资料,于是开始用生动易懂、视觉化的方式来写这本教程。
Python入门书目录
第一章 为什么选择Python?
第二章 现在就开始
第三章 变量与字符串
第四章 函数的魔法
第五章 循环与判断
第六章 数据结构
第七章 类与可口可乐
第八章 开始使用第三方库
高效学习法的小技巧
1、精简:学习最核心的关键知识;
2、理解:运用类比、视觉化的方法来理解这些核心知识;
3、实践:构建自己的知识体系之后,再通过实践去逐渐完善知识体系。
编程小白的第一本Python入门书截图


相关资料1:
- 《汇编语言编程实践及上机指导》.pdf
- 《Visual C++ 2017网络编程实战》.pdf
- javascript高效图形编程 中文版
- 《Linux网络编程》(第2版).pdf
- 《精通Linux C编程-2009》.pdf
- c++并发编程实战 中文版
- 《现代JavaScript编程:经典范例与实践技巧》.pdf
- 《编程小白的第一本 Python 入门书》侯爵.pdf .epub
- 《Java编程方法论响应式RxJava与代码设计实战》.pdf
- 《Rust编程之道在线》.pdf
- 编程珠玑.pdf
- Java线程与并发编程实践.pdf
- 《JAVA并发编程实践》(中文).pdf
- 《R并行编程实战》高性能计算技术丛书.pdf .epub
- 多处理器编程的艺术.pdf